I’ve written before about how I used EPrints as a back end for WordPress, which was a front end for some OERs which are aimed at anyone wanting to learn how to sketch. I didn’t really know where I was going with it, but it worked out OK. I’ve also written about how WordPress can be used for scholarly publishing with the addition of a few plugins. In that post, I showed how I deposited my MA Dissertation into EPrints via RSS from WordPress. I’m going to take a similar approach with the OERs we’ve created for the ChemistryFM project, using the repository as canonical storage and WordPress as a front end for the course. I think that for these reasons, I was asked to provide a brief ‘position paper’ for next week’s JISC CETIS event on repositories and the open web. ((The distinction between the open web and the social web isn’t very clear on the CETIS event page. I think that the open web is not necessarily social and that the social web is not necessarily open. For me, the open web refers to a distributed web built on open source and open standards like HTML, RSS, RDF, OAuth, OpenID. Although the two are converging, Twitter for example is not as good an example as Status.net in terms of the open web, but a better example of the social web in terms of its uptake.))
My position is pretty straight forward really. I don’t think it’s worth developing social features for repositories when there is already an abundance of social software available. It’s a waste of time and effort and the repository scene will never be able to trump the features that the social web scene offers and that people increasingly expect to use. The social web scene is largely market driven (people working in profit making companies develop much of the social web software) and without constantly innovating, businesses fail. Repositories, on the whole, are not developed for profit and do not need to innovate for the sake of something new that will drive revenue. That is a good position to be in. Why change it? When repositories start competing for features with social web software, it is the beginning of the end for them.
EPrints offers versioned storage for the preservation of digital objects and a rich amount of data in a number of formats can be harvested and exported from each EPrint. The significance of the software is the exposure of its data to Google, as you will see from looking at the web analytics for any repository.
In thinking about how to join EPrints to the social web, I’ve toyed with the idea of a socialrepo, where WordPress harvests one or more feeds from the repository. With a little design work, WordPress could be the defacto front end for the repository providing all the social features of a mature blogging platform.
We’ve also commissioned a couple of plugins for EPrints that extends the reach both to and from EPrints. The first is a simple widget that can be placed on any web page and provides a way for a member of staff to upload a paper to their EPrints workspace. The second is an XML-RPC plugin that allows you to post a summary of your EPrint to your blog at the end of the deposit process so that the item can be advertised in a place more meaningful to you than an institutional repository and discussed alongside all your other academic blogging.
As I’ve shown with my own dissertation, EPrints can consume RSS feeds and if we want to add social web compatibility to EPrints, why not focus on improving the ingest process so that data can be harvested from the feed to populate the cataloguing fields? And while we’re at it, recall that the social web is rich in multimedia. EPrints could be much improved in how it ingests multimedia and the batch editing functionality that is essential when dealing with hundred of images, for example. Much could be done on the inside of EPrints, but on the outside, EPrints is an excellent example of the open web but a poor example of the social web. But let’s not beat ourselves up about it. The social web thrives on the technologies of the open web. Give it what it needs to thrive and make it easier for users to feed the beast.
I’m at JISC’s #dev8D conference. There’s no end of developer challenges but I’m not a developer. Still, here’s an idea that maybe someone will pick up and run with:
The use of eBook readers is on the rise. Anyone with an iPhone, Android phone, as well as Kindles and Sony Readers, has an eBook reader.
Institutional Repositories provide scholarly articles in PDF format, which eBook readers don’t handle very well at all, especially the phone versions.
Why not provide a Word-to-PDF conversion facility in your repository? EPrints currently offers Word-to-PDF conversion durinng the deposit process. Why not Word-to-ePub format, too?
Why not provide an ePub file as an alternative to the PDF download? ePub is a free, open, standards-based (XHTML/CSS) file format for eBook Readers. There are many advantages for the reader to having an ePub version rather than a PDF version when using an e-Book reader. i.e. better page navigation, search, bookmarks, variable font sizing.
There are PDF-to-ePub converters on the web, so technically it’s possible. They are a bit hit and miss, but so are the Word-to-PDF converters.
Anyone interested? I’d be keen to help if required.
These are slides to accompany an eight minute ‘Lightning Talk’ for the dev8D conference in London, 24-27th February 2010. Each slide is a link to a blog post I have written on ways to use WordPress and WordPress Multi User, that are not about blogging.
I repeat this to people all the time. If I write it down here, then I only have to share a link 😉
RSS feeds are a very popular way of syndicating content from one source website to another subscribing website.
Some university websites, such as the Institutional Repository or University blogs, produce RSS feeds but not all university websites can easily subscribe to them. However, by using ‘feed2js’, any website can display a syndicated news feed in just a few steps. This way, you can embed your blog or publication list in Blackboard or on your personal web profile, for example.
Creating a publications list from the repository
We use EPrints as our Institutional Repository. EPrints provides news feeds (RSS, RSS2, Atom) for every search query. Therefore you can create a news feed of publications by Faculty, School, Department, Research Team or Staff member. Having created the news feed, you can then display that list of publications on any web page of your choice.
Click on the image to see a real example
The advantage of this is that every time you deposit something new in the repository, the list will automatically update on your chosen web page. You never need to edit your publications list again.
Steps to embedding your feed
Create your publications list. Use the Advanced Search page to construct your publications list. If you want a personal publications list, simply search for your name. If you have a common name, your search may return publications that belong to someone else. In that case, you should keyword all your repository items with a unique ‘key’, such as ‘q73g’. You can then search for that keyword and your name and only your items will be returned by the search.
Search results
Copy your feed URL. Typically, you need to right-click on the orange RSS 2.0 icon on the search results page and copy the link.
Go to http://feed2js.org/index.php?s=build and paste your link into the URL box. If you are a member of the University of Lincoln, contact me for a better link, hosted at the university.
From this point on, you can click the ‘Preview Feed’ button at any time to see what your feed will look like. Read the listed options carefully. They allow you to choose whether you wish to display the title of the feed; whether you wish to show the full content of the feed or just the titles; whether you wish to show images or video content in the feed (if there is any in the original source), etc. Experiment by previewing the feed to see what looks best for you.
Previewing a feed
When you are happy with your feed, click the ‘Generate Javascript’ button. Copy everything inside the Get Your Code Here box. Note how the box scrolls. Copy it all!
Example generated javascript
Paste the javascript into the appropriate place in your website’s HTML code. Save your web page and examine your work. The embedded feed should fit in well with your existing web site design and use the colour scheme you have chosen for your site. If you wish to make the publications list stand out from your web page, you should read the page about dressing up your output.
There is no more you need to do. The feed will automatically update every hour or so with any new content from the source website.
I’ve just knocked up a ‘Social Repo‘ site and would be keen to get some feedback on the general idea.
It’s a WordPress site in microblog mode driven by feeds from our repo via the FeedWordPress plugin. Just an experiment in automating something similar to our Post2Blog plugin.
As a way of making EPrints content more ‘social’, I thought that specific subject feeds from different IRs could be aggregated into a single subject site where interested people could follow and comment on the research outputs.
I’m a fan of aaaargh.org which is a site where people share hard-to-obtain texts, mostly academic level material and largely related to critical, social theory. There’s a discussion board attached to it, too. No-one really controls it and it’s a great way of finding hard to obtain texts 🙂
Along loosely similar lines, I was thinking earlier that IRs could aggregate their feeds into a site, like my example, that provided a way to search, filter and discuss the source research outputs. If there was a site that aggregated feeds from IRs around the world, pulling in only content relating to critical, social theory, for example, had a twitter account attached, too, as well as useful RSS feeds of its own, I’d be keen to follow it and contribute to the discussion of work as it appeared and looked of interest.
I can imagine that some texts could spark quite detailed threaded discussions.
One way to improve my quick example would be to show the EPrints abstract in the post content below the citation. Alas, that’s not in the source EPrints feed right now. I would also make a few tweaks to the theme so that the permalinks didn’t all point to the source record, but that the source link was clearly provided.
The plugin that we created for the JISCPress project could provide a background service to create semantic tags and do term extraction on the abstract, to automate keywords for each item. Crikey! we could even use the other Linked Data plugin we developed and push the RDF to the Talis Platform, aggregating Linked Data around subject feeds from Institutional Repositories.
I’m sure I can think of more improvements, but as a 30 min exercise, I’ve found it interesting. I think that once a Repo record becomes joined to a WordPress record, it’s got a lot more going for it in terms of added levels of interaction and malleability. Any thoughts?
Working on the JISCPress project, I’ve been thinking quite a lot about scholarly publishing on the web, and in particular with WordPress. This morning, I read a post over on the ArchivePress blog about some WordPress plugins which are useful additions for creating a scholarly blog and it got me thinking a bit more about what features WordPress would need to support scholarly publishing.
JISCPress does away with the idea that WordPress is a blogging tool, and instead uses WordPress Multi-User as a document publishing platform, where one site or ‘blog’ is a document. The way WPMU is structured means that despite serving multiple (potentially millions) of document sites, the platform remains relatively ‘lightweight’ as each document site generates just a handful of additional database tables, while sharing the same administrative core as a single WordPress install. So, 100 WordPress blogs on WPMU is nothing like the equivalent of running 100 separate WordPress blogs, both from the point of resource requirements and administration. In fact, quite soon, there will be no such thing as WPMU as the two products are going to be merged and because they share 90%+ of the same code already, it’s not too difficult to achieve. ((Has anyone done a diff on the two code bases to measure exactly what percentage of the code is shared between WP and WPMU?))
Anyway, my point here is to discuss whether WordPress can be extended to accommodate most conventions found in scholarly publishing and where it is lacking, to identify the development work required to meet the needs of most academic who wish to write on and publish to the web. ((Actually, I think I’ll save the discussion of its shortfalls for my next post. This one is already long enough.))
Scholarly publishing extends to a wide variety of published outputs. As a Content Management System (CMS) and technology development platform, I believe that WordPress has the potential to support any type of scholarly publishing that the web supports. It is extremely extensible, as can be seen from the 6000+ plugins that are available. However, what I’m interested in is what can be done now, by an academic wishing to publish their work through the use of WordPress acting as a CMS. What can be achieved with a few quid ((I pay $5/year for my domain name and as many sub-domains as I need. I pay $10/month for my hosting with unlimited storage and bandwidth.)) to self-host WordPress so that a few plugins can be installed and a well structured, typical, scholarly paper can be published.
My Dissertation
For some time, I’ve been meaning to publish my MA dissertation. Back in 2002, I undertook some unique research which has not, to my knowledge, been repeated and I think there is some value in having it easily accessible on the web. I have an OpenOffice file and a PDF and, in the course of a morning, have published it under my own domain. The reason I did not publish it on the university WPMU platform is because I have been experimenting with different plugins and did not want to install plugins that were untested or we may not support long-term. In this case, I’ve used a single WordPress installation, but ideally an individual researcher, group of researchers or research institution, would run a WPMU installation which allowed multiple documents to be authored individually or collaboratively ((Like any decent CMS, WordPress supports role-based authoring and editing and maintains a revision history of edits, auto-saved once per minute. Revisions can be compared alongside of each other.)) and published directly to the web as XHTML.
BuddyPress, by the way, can make the experience even more natural, not only because it is based around a community of like-minded people writing together on the same web publishing platform, but also because, with a few tweaks here and there, we can move away from the language of blogs and towards the language of documents.
Enough of BuddyPress on WPMU for now and back to my dissertation. I set up the site in ten minutes, without using FTP or a command line because I use a host that provides a one-click install of WordPress and WordPress allows you to search for and install plugins from its Dashboard, rather than having to use FTP. Once the site was installed, I then made some basic changes to the settings, turning on XML-RPC and AtomPub, so that, if I decided to, I could publish to the site using my Word Processor. ((On a scholarly WPMU installation, plugins could be pre-installed and activated, a default theme selected and settings tweaked so very little work is required by the academic author prior to writing her document.)) I didn’t use this in the end, but trust me, it works very well using recent versions of MS Word, Open Office (free) and other blogging clients such as MS Live Writer (free).
So, what are the common characteristics of an academic paper? What does WordPress have to support to provide functionality that meets most scholars’ publishing requirements? I scratched my head (and asked on Twitter) and came up with the following:
footnotes/endnotes
citations
use of LaTeX (sciences)
tables
images
bibliography
sub-headings
annexes
appendices
dedication
abstract
table of contents
index to figures
introduction
exposition
conclusion
Many of these are supported in WordPress by default and don’t require any additional plugins (tables, images, sub-headings, annexes, appendices, dedication, abstract, introduction, exposition, conclusion, are all either basic literary conventions or just part of a simply structured document).
For additional support, I installed digress.it, which we have funded through the JISCPress project. This is a WordPress plugin which allows readers to comment on the paragraphs of a document, rather than at the document section level. We’re adding a lot more functionality to meet the objectives of the JISCPress project, but I chose digress.it, principally for the reason that it is designed to turn a WordPress blog into a document site. I could have used any other WordPress theme, but digress.it automatically creates a Table of Contents and allows you to re-order WordPress posts when they are read so that you don’t have to author your document in reverse or adjust the publication dates so the document sections appear in the correct order.
My dissertation published using digress.it
I added the abstract for my dissertation to the ‘about’ page, so it shows up on the front of the site. I also uploaded a PDF version so that people can download it directly. You’ll see that I also added some links to a related book and DVD, which will certainly appeal to people who are interested in my dissertation. The links pull an image and some basic metadata from Amazon, using the Amazon Machine Tags plugin. This could be used to link to the book in which your article is published and earn you money in click referrals. An alternative, would be the Open Book Book Data plugin, which retrieves a book cover and metadata from Open Library, where your book may already be catalogued. If it’s not on Open Library, catalogue it!
After setting this up, I installed a few more plugins:
Dublin Core for WordPress: Automatically adds ten Dublin Core metadata elements to the document mark up.
wp-footnotes: This allows you to easily add footnotes to your document by enclosing your footnote in double parentheses. ((I am using the plugin on this blog!))
OAI-ORE Resource Map: Automatically marks up the document sections with a OAI-ORE 1.0 resource map.
Google Analyticator: Adds Google Analytics support so you can collect statistics on the readership of your document.
WP Calais Archive Tagger: Analyses your entire document and automatically keywords each section, using the Open Calais API.
Search API: WordPress comes with search built in, but there is a new search API which will eventually make its way into the WordPress core. I’ve installed the plugin to provide full-text search across the document. It can also add Google Search to your document site.
wp-super-cache: This is simple to install and will significantly speed up your document site, making it a pleasure to navigate through and read 🙂
Plugins I didn’t use
wp-latex: Although I didn’t need it for my dissertation, it’s worth noting that WordPress supports the use of.
Academic Citation: You need to add a line of code to your theme for this to display. It supports the concept of an article being a single blog post, rather than a ‘document site’ and displays a variety of citation formats for readers to use.
Do you know of any other plugins for a scholarly blog?
The Beauty of Feeds
The other useful thing about managing a document using WordPress and in particular, using digress.it, is that you automatically get RSS/Atom feeds for the document. I’ve already discussed these in detail. It means that I was able to read my document in my feed reader, with footnotes and images displayed correctly.
See how nicely the formatting is preserved. is also rendered correctly in feed readers.
Reading my dissertation in Google Reader
You’ll see that the document sections are listed in order; that is, first section on top. As I noted above, blogs list posts in reverse (most recent first), so I sorted the feed items in Yahoo Pipes and sorted it in ascending order. Yahoo Pipes exports as RSS and it’s that feed that I subscribed to in Google Reader. Wouldn’t it be nice, if I could import my document feed into an Institutional Repository? Wait a minute, I can! 🙂
Click to see the item in the repository
When importing the default feed, the HTML output is accurate but in reverse order, while the RSS output from Yahoo Pipes didn’t import into EPrints very cleanly at all. I’ll work on this. UPDATE: Forget Yahoo Pipes. WordPress feeds can be sorted with a switch added to the URL: http://example.com/feed/?orderby=post_date&order=ASC
So there it is. An academic paper, published to the web using a modern CMS which supports most authoring and publishing requirements. I would favour an institutional WPMU platform for academics to author directly to, publish their pre-print to the web for open access and detailed comment, and import their RSS feed into the repository. As a proof of concept, I’m quite pleased with this. We are currently developing a widget that can be embedded in a web page or WordPress sidebar and allow a member of staff to upload a document or zipped folder of documents to the Institutional Repository. I wonder if we can also support the import of a feed from the widget, too?
So, what would your requirements be? Tell me and I’ll do my best to test WordPress against them.
A post to note that I have successfully deposited a document into our institutional repository from my Facebook account using the Facebook SWORD app, written by Stuart Lewis.
There’s a few things worth mentioning: It’s a 3.1.1 EPrints IR, hosted at our university and maintained by EPrints Services. EPrints has supported SWORD since v3.1. Originally, the FB app didn’t work for the following reasons:
The ‘Depositing on behalf of’ field has to be left empty. I was told by Seb at EPrints Services that this is ‘disabled by default’.
We use LDAP for authentication and the IR configuration needed to be tweaked to account for this when depositing via SWORD.
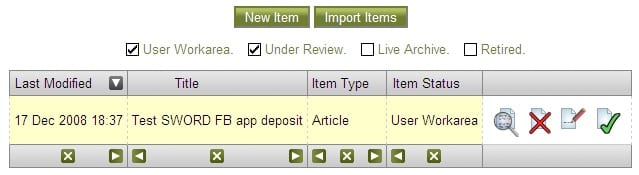
Once we’d overcome these issues, my ‘test.txt’ doc was successfully deposited from my desktop to the University of Lincoln IR via Facebook:
…with a few caveats:
The app announced ‘Item Deposited!’ and gave a URL which resulted in a 404 dead link http://eprints.lincoln.ac.uk/sword-app/collections/1738/deposit. I don’t know why. I thought it was because I wasn’t logged in to the IR, but even after logging in, the link was dead.
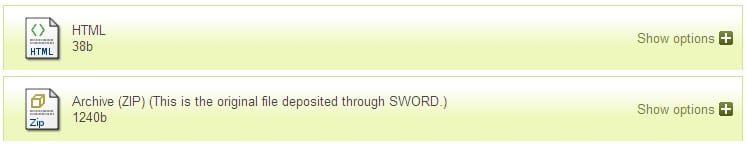
The app (maybe it’s defined in the SWORD spec, I haven’t checked), zipped up my metadata and document, which resulted in depositing two items: My test.txt document and the original zip file were both showing in my item list. This could be because of the way our IR is configured to unpack zip folders. I don’t know.
The metadata mapping was partially successful. The referreed status didn’t map across at all and the URL reference I gave mapped to the ‘Identification number’ field in EPrints, rather than the ‘Related URLs’ field, which was what I was expecting. Maybe the SWORD app field could be renamed ‘Identification URL/DOI’ or similar? The title, abstract and my name were correctly mapped. It’s a shame that my email address wasn’t autocompleted as it would be if I were depositing through the normal EPrints workflow.
Despite these issues, it’s good to see this working in principle and I imagine that the above could be rectified quite easily. Perhaps someone can offer their solutions here?
As Stuart notes on his blog, the main value in this kind of app is the ability to broadcast to your Facebook friends that you’ve just deposited something in an IR. My main gripe, however, would be that it doesn’t make the deposit process any easier, which is what interests me about the SWORD protocol. Working this way…
I have to use two applications to make my document public, the benefit being that other people are told about what I’ve just done.
The EPrints URL that the app points to, even if it was working, points to a non-public space, so my friends don’t have a direct link to the document from within Facebook.
The metadata fields in the present version of the app, are not configurable which means that I have to add more metadata through the EPrints interface.
Finally, it does seem odd to upload a document from my desktop to Facebook only to send it to another application and finish off the process of deposit there. It would be more useful, if I could deposit files that I already hold in Facebook. I don’t use Facebook enough to really know if there are apps that allow you to create documents within Facebook, but if there were, then perhaps Facebook could be used as a (collaborative?) working space and the SWORD app used to deposit final versions to an IR.









 .
.